您现在的位置是:网站首页> 编程资料编程资料
关于数据处理包dplyr的函数用法总结_其它综合_
![]() 2023-05-27
964人已围观
2023-05-27
964人已围观
简介 关于数据处理包dplyr的函数用法总结_其它综合_
dplyr专注处理dataframe对象, 并提供更稳健的与其它数据库对象间的接口。
一、5个关键的数据处理函数:
select() 返回列的子集
filter() 返回行的子集
arrange() 根据一个或多个变量对行排序。
mutate() 使用已有数据创建新的列
summarise() 对各个群组汇总计算并返回一维结果。
Tips:
1、select()
Dplyr包有下列辅助函数,用于在select()中选择变量:
starts_with("X"): 以 "X"开头的变量名
ends_with("X"): 以 "X"结束的变量名
contains("X"): 包含 "X"的变量名
matches("X"): 匹配正则表达式“x"的变量名
num_range("x", 1:5): 变量名为 x01, x02, x03, x04 and x05
one_of(x): 出现在字符向量x中的所有变量名
在select()中直接使用列时不需要引用"",但使用上述辅助函数时必须引用""。
2、filter()
R 有一系列逻辑表达式可用于filter()中:
x < y;x <= y;x == y;x != y;x >= y;x > y;x %in% c(a, b, c)
示例:
filter(df, a > 0, b > 0)
filter(df, !is.na(x))
3、arrange()
arrange()默认从小到大排序,在arrange()中使用desc()作用于变量可以使之从大到小排序.
4、mutate()
mutate()允许在同一次调用中使用新变量来创建下一个变量,例如:
mutate(my_df, x = a + b, y = x + c)
5、 summarise()
R的下列聚合函数可用于 summarise()中
- min(x) - 最小值.
- max(x) - 最大值
- mean(x) - 平均值
- median(x) - 中位数
- quantile(x, p) - x的第P个分位数
- sd(x) -标准差
- var(x) - 方差
- IQR(x) - 四分位数
- diff(range(x)) - x值的范围
dplyr包自身提供了一些有用的聚合函数:
- first(x) - 向量x中的第1个元素
- last(x) - 向量x中的最后1个元素
- nth(x, n) - 向量x中的第n个元素
- n() - data.frame中的行数或 summarise() 描述的观测组的数量
- n_distinct(x) - 向量x中唯一值的数量
二、管道函数%>%
dplyr包中特有的管道函数%>%,将上一个函数的输出作为下一个函数的输入。
%>%运算符允许从参数列表中提取函数的第一个参数,并放置在%>%前面。
下面两条指令相等:
mean(c(1, 2, 3, NA), na.rm = TRUE)
c(1, 2, 3, NA) %>% mean(na.rm = TRUE)
三、分组函数group_by()
对数据集定义群组。然后可对各个群组分别进行汇总统计。
通过 group_by() 添加了分组信息后,mutate(), arrange() 和 summarise() 函数会自动对这些 tbl 类数据执行分组操作。
group_by(dataframe,colnames1,colnames2,…)
四、连接数据(joins)
1、6种连接函数如下:
left_join(dataset1,dataset2)
right_join(dataset1,dataset2)
inner_join(dataset1,dataset2,by=c(“”))
full_join(dataset1,dataset2, by = c("first", "last"))
semi_join(dataset1,dataset2, by = c("first", "last"))
anti_join(dataset1,dataset2, by = c("first", "last"))
前4种属于变形连接(mutating joins),后2种属于过滤连接(filtering joins)。
semi-joins基于第二个数据集的信息来过滤第一个数据集的数据。anti-joins找出合并时哪些行不能匹配第二个数据集

2、key值
R语言的 data frames可在 row.names属性中存储重要信息,虽然不是存储数据的好方式却很常见。如果数据集的主关键字在row.names中,将难以与其他数据集连接。一种解决方法是使用tibble包(tibble:a data frame with class tbl_df)中的rownames_to_column()函数,返回该数据集的副本,并且行名作为一列增加到该数据中。
library(tibble)
rownames_to_column(data, var="name")
如果两个数据集有相同的列名,但代表的事物不同,并且by参数不包含这些重复的列名,dplyr会忽略这些列名,并对相同的列名增加.x和 .y来帮助区分列。
当两个数据集中相同的事物有不同的列名,要完成合并,将by设置为一个命名向量。向量的名字为主数据集中的列名,向量的值为第二个数据集中的列名。例如:
x %>% left_join(y, by = c("x.name" = "y.name"))
完成连接后保留主数据集中的列名。
3、多个数据集的连接
Purrr包中的 reduce()函数对多个数据集重复应用某函数,可用于连接多个数据集,与dplyr的join类函数配合使用,例如:
library(purrr)
list(data1,data2,data3) %>% reduce(left_join,by = c("first","last"))
五、集合操作(set operations)
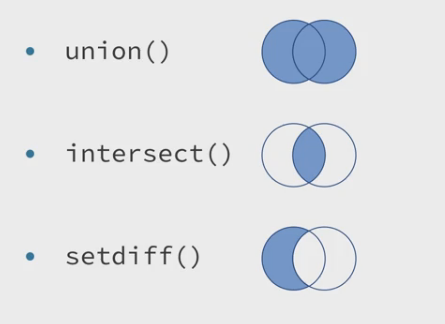
dplyr提供了intersection、union和setdiff用于获得数据集的交集、并集和差集。
六、组装数据assembling data
使用如下函数:
bind_rows()
bind_cols() :将多个data frame合成单个data frame
data_frame() : 将一系列列向量组合成data frame
as_data_frame() :将list转换成data frame
以上这篇关于数据处理包dplyr的函数用法总结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。





